Python-сообщество
Форум сайта python.su
- Вы не вошли.
Уведомления
- Начало
- » Python для новичков
- » Линейная регрессия: accuracy 95%, но полная ерунда
![[RSS Feed]](/static/djangobb_forum/img/feed-icon-small.png "[RSS Feed]")
#1 Фев. 20, 2017 07:47:32
- m0rtal
-

-
- Зарегистрирован: 2017-01-20
- Сообщения: 22
- Репутация:
 0
0 
- Профиль Отправить e-mail

Линейная регрессия: accuracy 95%, но полная ерунда
Есть некий датафрейм pandasdf, длиной порядка 5000 строк.
Делаем с ними вот такое:
pandasdf['label'] = pandasdf[forecast_col].shift(-forecast_out) # смещаем данные о цене назад на n строк, "имитируя" будущее X = np.array(pandasdf.drop(['label'], 1)) # features X = preprocessing.scale(X) # нормализуем данные X_lately = X[-forecast_out:] # берём только данные без labels для прогноза X = X[:-forecast_out] # не учитываем данные без labels pandasdf.dropna(inplace=True) # удаляем строки с пустыми значениями y = np.array(pandasdf['label']) # labels X_train, X_test, y_train, y_test = cross_validation.train_test_split(X, y, test_size=0.3) # проходим кросс-валидацию на 30% данных (test_size=0.3) clf = LinearRegression(n_jobs=-1) # указываем классификатор clf.fit(X_train, y_train) # обучаемся accuracy = int(clf.score(X_test, y_test) * 100) # проверяем точность с помощью кросс-валидации forecast_set = clf.predict(X_lately) # предсказываем на последних/неизвестных данных
И получаем “предсказание” прошлого с точностью 95%:
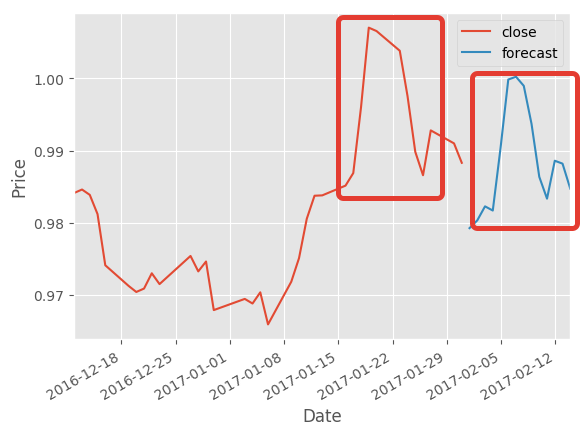
Отредактировано m0rtal (Фев. 20, 2017 09:13:33)
Офлайн
#2 Фев. 20, 2017 08:33:52
- m0rtal
-
-
- Зарегистрирован: 2017-01-20
- Сообщения: 22
- Репутация:
0
- Профиль Отправить e-mail
Линейная регрессия: accuracy 95%, но полная ерунда
Для наглядности, а может и для себя, чтобы лучше понимать.
Исходный датафрейм
pandasdf['label'] = pandasdf[forecast_col].shift(-forecast_out)

В колонке Label - данные из Price, смещённые на N строк назад.
Берём из него все колонки, кроме последней:
X = np.array(pandasdf.drop(['label'], 1))
Нормализуем:
X = preprocessing.scale(X)
Берём последние N строк, для которых нет Labels (мы же сдвинули их назад, верно?):
X_lately = X[-forecast_out:]
Для обучения берём все строки датафрейма кроме последних N (которые у нас в X_lately):
X = X[:-forecast_out] y = np.array(pandasdf['label'])[:-forecast_out]
Разбиваем данные для кросс-валидации:
X_train, X_test, y_train, y_test = cross_validation.train_test_split(X, y, test_size=0.3)
Ну и собственно обучаемся:
clf = LinearRegression(n_jobs=-1) clf.fit(X_train, y_train)
Проверяем точность предсказания, получаем 95..97%:
accuracy = int(clf.score(X_test, y_test) * 100)
Получаем набор предсказанных данных на последних N строках:
forecast_set = clf.predict(X_lately)
Ожидаем получить информацию о следующих N строках, а получаем достоверную информацию о прошлом.
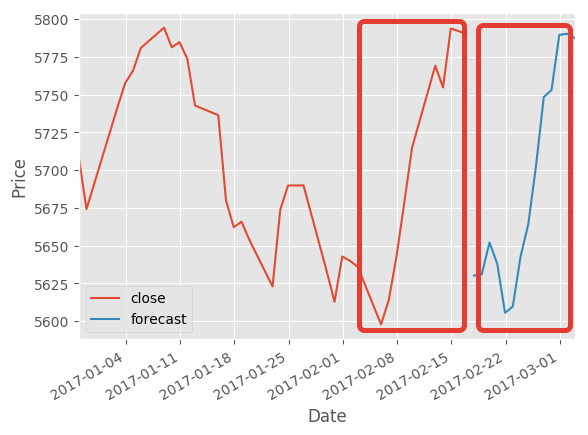
Вроде логика правильная, но что-то всё же не так…
Отредактировано m0rtal (Фев. 20, 2017 09:12:12)
Офлайн
#3 Фев. 21, 2017 09:04:27
- noob_saibot
-

-
- Зарегистрирован: 2013-09-11
- Сообщения: 495
- Репутация:
20
- Профиль Отправить e-mail

Линейная регрессия: accuracy 95%, но полная ерунда
Time series dependencies - проверьте свою логику тут.
PS. Нормализация и масштабирование это разные вещи
PSS. Если я все правильно понял, то у вас не CV, а данные просто сплитятся на тестовую и обучающую подвыборки, пусть и перемешиваясь. Для реализации кросс-валидации я например использую (from sklearn.model_selection import cross_val_score).
PSSS. Кстати обновите sklearn.
PSSSS. Кстати линейная модель на временных рядах, для реальных данных не подходит. пруф по ссылке выше (ну и если посмотреть на то как это под капотом работает станет понятно).
Отредактировано noob_saibot (Фев. 21, 2017 09:32:27)
Офлайн
#4 Фев. 21, 2017 20:40:18
- m0rtal
-
-
- Зарегистрирован: 2017-01-20
- Сообщения: 22
- Репутация:
0
- Профиль Отправить e-mail
Линейная регрессия: accuracy 95%, но полная ерунда
noob_saibot
Time series dependencies - проверьте свою логику тут.
вроде “то”… стр. 37, создаём из features матрицу X, которой с помощью эстиматора подбираем веса коэффициентов, чтобы получить y.
PS. Нормализация и масштабирование это разные вещи
я не волшебник, я только учусь ))
спасибо, буду осторожнее в терминологии
PSS. Если я все правильно понял, то у вас не CV, а данные просто сплитятся на тестовую и обучающую подвыборки, пусть и перемешиваясь. Для реализации кросс-валидации я например использую (from sklearn.model_selection import cross_val_score).
Хм. Попробовал np.mean(cross_val_score(clf, X, y, cv=10)), получились совсем другие цифры. Только толку с них? Мне эстиматор всё равно продолжает предсказывать прошлое с великолепной точностью ))
PSSS. Кстати обновите sklearn.
0.18.1. Или бета нужна?
PSSSS. Кстати линейная модель на временных рядах, для реальных данных не подходит. пруф по ссылке выше (ну и если посмотреть на то как это под капотом работает станет понятно).Да тут я даже ни секунды не сомневаюсь. Я учусь, хотелось попробовать что-то простое… и на нём так дико застрял…
А на будущее хочу поэкспериментировать с эстиматорами отсюда: http://scikit-learn.org/stable/tutorial/machine_learning_map/index.html
Я правильно понимаю, Lasso или ElasticNet должны быть правильным выбором?
Отредактировано m0rtal (Фев. 21, 2017 20:42:29)
Офлайн
#5 Фев. 22, 2017 06:35:16
- noob_saibot
-
-
- Зарегистрирован: 2013-09-11
- Сообщения: 495
- Репутация:
20
- Профиль Отправить e-mail
Линейная регрессия: accuracy 95%, но полная ерунда
m0rtalЯ не об этом, вы прямо "Time series dependencies" найдите на странице, там расписаны моделирования зависимостей. Вы должны учить свою модель предсказывать будущие значения по предыдущим. Ну а если у вас известны лейблы для будущих моделей, то делаете модель в которой будут и лейблы и предыдущие значения учитываться.
вроде “то”… стр. 37, создаём из features матрицу X, которой с помощью эстиматора подбираем веса коэффициентов, чтобы получить y.
m0rtalЯ подумал что у вас старая версия поскольку модуль sklearn.cross_validation скопировали в model_selection начиная с 0.18 версии.
0.18.1. Или бета нужна?
m0rtalПредсказанием временных рядов не занимался, но в тренде видел нейронные сети, поэтому реализуете их на theano/lasagne. Ну и задачу для обучения вы выбрали не самую простую, воспользуйтесь www.kaggle.com, там есть задачи и данные (тот же Титаник или классификация ирисов), и очень много подробно расписанных стратегий решения (правда порой без обоснования). + Обязательно считаю нужным ознакомится с курсом Воронцова
Я правильно понимаю, Lasso или ElasticNet должны быть правильным выбором?
Отредактировано noob_saibot (Фев. 22, 2017 06:36:31)
Офлайн
#6 Фев. 22, 2017 08:14:35
- m0rtal
-
-
- Зарегистрирован: 2017-01-20
- Сообщения: 22
- Репутация:
0
- Профиль Отправить e-mail
Линейная регрессия: accuracy 95%, но полная ерунда
noob_saibotОх… ушёл читать/смотреть )))
Курс Воронцова выкачал давно, никак руки не доходили посмотреть, столько всего интересного )))
Огромное спасибо за заданные векторы для обучения, в таком море информации новичку непросто

PS: а sklearn.cross_validation я уже поменял на from sklearn.model_selection import train_test_split
Кстати, пока так и не понял, почему cross_val_score работает только на линейных регрессиях? Я пробовал на: LinearRegression, Lasso, ElasticNet, Ridge, SVR, RandomForestRegressor - завелось только на первых двух. В документации как-то не вижу ограничений…
Офлайн
#7 Фев. 22, 2017 08:29:39
- noob_saibot
-
-
- Зарегистрирован: 2013-09-11
- Сообщения: 495
- Репутация:
20
- Профиль Отправить e-mail
Линейная регрессия: accuracy 95%, но полная ерунда
m0rtalПокажите ошибку.
завелось только на первых двух
Офлайн
#8 Фев. 22, 2017 15:30:58
- m0rtal
-
-
- Зарегистрирован: 2017-01-20
- Сообщения: 22
- Репутация:
0
- Профиль Отправить e-mail
Линейная регрессия: accuracy 95%, но полная ерунда
noob_saibotээээ…. сегодня уже никакой ошибки не выдаёт… может, я ночью что-то не то вчера написал… пардон ))
Офлайн
#9 Фев. 22, 2017 17:31:58
- m0rtal
-
-
- Зарегистрирован: 2017-01-20
- Сообщения: 22
- Репутация:
0
- Профиль Отправить e-mail
Линейная регрессия: accuracy 95%, но полная ерунда
А TimeSeriesSplit разве не будет лучшим вариантом в моём случае?
Офлайн
#10 Фев. 23, 2017 10:33:22
- m0rtal
-
-
- Зарегистрирован: 2017-01-20
- Сообщения: 22
- Репутация:
0
- Профиль Отправить e-mail
Линейная регрессия: accuracy 95%, но полная ерунда
Проблема оказалась в жуткой автокорреляции в 97% между close и label. Для алгоритма оказалось очевидным, что раз такая взаимосвязь, то label ~ close * 0.97.
Думаю, как победить.
Офлайн
- Начало
- » Python для новичков
-
» Линейная регрессия: accuracy 95%, но полная ерунда