Python-сообщество
Форум сайта python.su
- Вы не вошли.
Уведомления
- Начало
- » Python для экспертов
- » Как раскрыть потенциал современных NVMe SSD при сохранении/загрузке коллекций обьектов?
![[RSS Feed]](/static/djangobb_forum/img/feed-icon-small.png "[RSS Feed]")
#1 Июль 20, 2021 22:42:25
- NVMeMaster
-

-
- Зарегистрирован: 2021-07-20
- Сообщения: 7
- Репутация:
 0
0 
- Профиль Отправить e-mail

Как раскрыть потенциал современных NVMe SSD при сохранении/загрузке коллекций обьектов?
Дано: быстрый 1Tb NVMe SSD от Samsung
Нужно: выжать максимальную скорость при загрузке кеша (больших коллекций обьектов - классы со slots)
На старте пайтон программы, загружаются самописные индексы, по ним производится поиск, отдается результат.
Сами коллекции можно как угодно переписать, в том числе в виде библиотеки на Rust (но хотелось бы сначала выжать максимум из пайтона)
Посоветуйте что можно попробовать?
Есть также рамдиск для тестов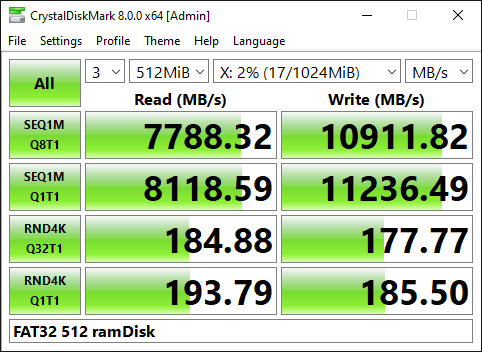

Отредактировано NVMeMaster (Июль 20, 2021 22:46:13)
Офлайн
#2 Июль 21, 2021 08:04:09
- doza_and
-

-
- От:
- Зарегистрирован: 2010-08-15
- Сообщения: 4138
- Репутация:
252
- Профиль Отправить e-mail

Как раскрыть потенциал современных NVMe SSD при сохранении/загрузке коллекций обьектов?
NVMeMasterНа мой взгляд вам прежде всего надо поменять подход, постановку задачи.
Посоветуйте что можно попробовать?
NVMeMasterПри такой постановке путь к цели бесконечный, всегда можно еще что-то придумать.
Нужно: выжать максимальную скорость при загрузке кеша
Вам надо определиться какой скорости вам достаточно.
SSD обычно имеют несколько каналов. Можно попробовать грузить объекты в несколько потоков (2-4).
Скорость загрузки пиклов достаточно высокая, врядли вы существенно выиграете от переписывания на компилируемые языки.
Офлайн
#3 Июль 22, 2021 11:14:40
- NVMeMaster
-
-
- Зарегистрирован: 2021-07-20
- Сообщения: 7
- Репутация:
0
- Профиль Отправить e-mail
Как раскрыть потенциал современных NVMe SSD при сохранении/загрузке коллекций обьектов?
Я думаю нужно читать и писать кеш в том же самом формате в каком он находится в оперативной памяти.
А чтобы эффективнее упаковать данные нужно использовать С или Rust массивы.
Как можно написать класс-обертку для превращения С-массива в рид-онли питон список?
Офлайн
#4 Июль 22, 2021 12:00:46
- Rodegast
-
-

- От: Пятигорск
- Зарегистрирован: 2007-12-28
- Сообщения: 2757
- Репутация:
184
- Профиль Отправить e-mail
Как раскрыть потенциал современных NVMe SSD при сохранении/загрузке коллекций обьектов?
> На старте пайтон программы, загружаются самописные индексы, по ним производится поиск, отдается результат.
Ничего не понятно. Какие индексы? Где они хранятся? Как хранятся данные на диске? В каком формате? Каким образом питоновские объекты записываются на диск?
Ели кому-то правда не нравится, то заранее извиняюсь.
Отредактировано Rodegast (Июль 22, 2021 12:38:37)
Офлайн
#5 Июль 22, 2021 13:30:34
- NVMeMaster
-
-
- Зарегистрирован: 2021-07-20
- Сообщения: 7
- Репутация:
0
- Профиль Отправить e-mail
Как раскрыть потенциал современных NVMe SSD при сохранении/загрузке коллекций обьектов?
В данный момент оно реализовано на простом pickle
Мне нужен быстрый поиск по ~8Gb текстовых файлов, логика поиска примерно такая же как в нотпад++
Только у меня индексы строятся заранее, а не в момент поиска.
Содержимое файлов загружается лениво (предпросмотр сделан на pyqt5 точно как на скриншоте. но графический режим и предпросмотр используется не всегда)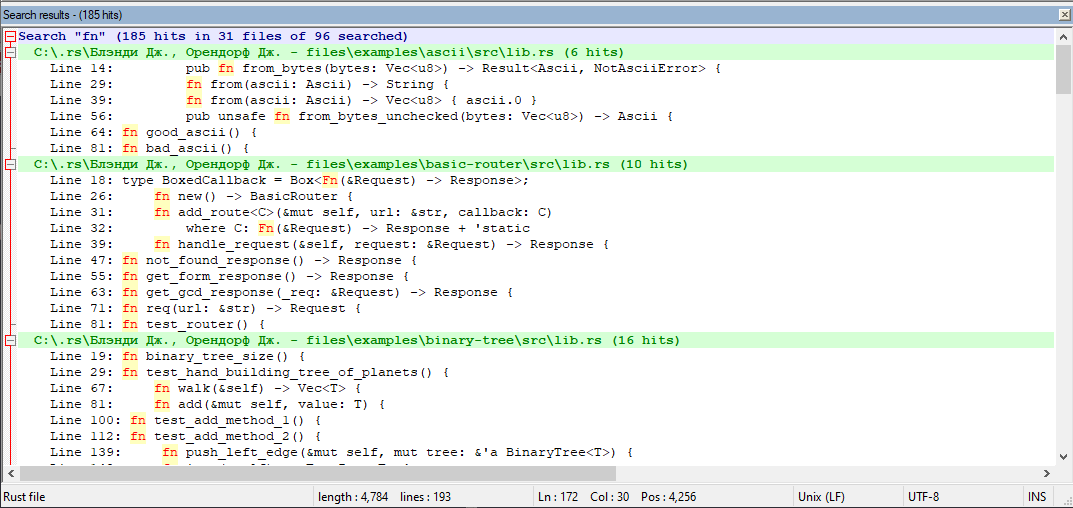
Если попытаться перевести скриншот в сишную структуру получится следующее:
struct SearchResult {
int file_path_hash; //file_path_hash == Python hash(file_path)
int str_start_index;
int line_number; //добавлено для предпросмотра в стиле нотпад++
int line_str_start_index; //для предпросмотра в стиле нотпад++
}
find_string будет именем файла, ну а содержимое файла - массив структур
Как видно я совсем отказался от хранения строки с file_path.
Вместо имени файла храню хеш пути к файлу и использую словарь int file_path_hash -> file_path в отдельном файле. (эту логику не нужно переписывать с Python на си)
Сейчас нужно компактно упаковать struct SearchResult в памяти.
А поскольку я выбросил все строки можно попробовать хранить это все в ПЛОСКОМ numpy.array
Вот так оно сериализуется в файл:
arr = np.array([ 2147483647, ord('a'), ord('b'), ord('c'), 2147483647 - 1, ord('q'), ord('w'), ord('e'), 2147483647 - 2, ord('a'), ord('s'), ord('d'), 2147483647 - 3, ord('z'), ord('x'), 2147483647 ]) file_name = 'np_array.dat' np.save(open(file_name, 'wb'), arr)
Отредактировано NVMeMaster (Июль 22, 2021 13:33:35)
Офлайн
#6 Июль 22, 2021 13:34:33
- FishHook
-
-

- От:
- Зарегистрирован: 2011-01-08
- Сообщения: 8312
- Репутация:
568
- Профиль Отправить e-mail
Как раскрыть потенциал современных NVMe SSD при сохранении/загрузке коллекций обьектов?
Мне нужен быстрый поиск по ~8Gb текстовых файловну вряд ли же вы первый кому понадобился “быстрый поиск по ~8Gb текстовых файлов”
что, совсем нет готового решения?
Офлайн
#7 Июль 22, 2021 13:47:44
- NVMeMaster
-
-
- Зарегистрирован: 2021-07-20
- Сообщения: 7
- Репутация:
0
- Профиль Отправить e-mail
Как раскрыть потенциал современных NVMe SSD при сохранении/загрузке коллекций обьектов?
Вокруг моего решения уже выстроено много кастомной логики, отказаться от нее не выйдет.
Если делать np.save() / np.load() в разных потоках это решит все проблемы.
В идеале - на каждый файл индекса - свой поток, но не более некоторого максимального числа потоков.
В следующей итерации индексер файлов можно написать на Rust, просто имитируя формат файлов с np.array
Как думаете стоит ли заморачиваться с numpy, или же сразу написать библиотеку-обертку над сишной или Rust структурой и массивами
Отредактировано NVMeMaster (Июль 22, 2021 13:54:32)
Офлайн
#8 Июль 22, 2021 18:21:19
- doza_and
-
-
- От:
- Зарегистрирован: 2010-08-15
- Сообщения: 4138
- Репутация:
252
- Профиль Отправить e-mail
Как раскрыть потенциал современных NVMe SSD при сохранении/загрузке коллекций обьектов?
NVMeMaster
Как думаете стоит ли заморачиваться с numpy, или же сразу написать библиотеку-обертку над сишной или Rust структурой и массивами
Лично у меня сложилось мнение что у вас сплошная каша в голове.
Начали вы с того что
NVMeMasterПотом оказывается что
Нужно: выжать максимальную скорость
NVMeMaster
Сейчас нужно компактно упаковать struct SearchResult в памяти.
Вы не приводите никаких требований ни по быстродействию ни по объему памяти, вообще никаких. Непонятно что у вас за индекс (это словари или еще чтото). Непонятно на каком железе вы это будете запускать (объем памяти объем диска, сколько ядер тактовая частота). 8 гиг на современных машинах целиком в память влезут.
NVMeMasterДля меня это означает что архитектура приложения никуда не годится. Я бы такое выкинул и написал заново.
Вокруг моего решения уже выстроено много кастомной логики, отказаться от нее не выйдет.
Я бы вам посоветовал для начала сравнить ваш индекс с существующими. Например с потнотекстовым поиском mongodb и с elastic search.
Я могу понять ваш подход если цель просто научиться языку и технологиям поиска. Но для продакшена обычно используют готовые, проверенные решения.
Офлайн
#9 Июль 23, 2021 01:55:01
- py.user.next
-
-
- От:
- Зарегистрирован: 2010-04-29
- Сообщения: 9885
- Репутация:
853
- Профиль Отправить e-mail

Как раскрыть потенциал современных NVMe SSD при сохранении/загрузке коллекций обьектов?
NVMeMasterТак это алгоритмически делается, скорее всего. В общем, опиши подробнее, какие файлы, что в них ищется. И опиши, что есть на данном этапе, как оно ищет (по какому алгоритму) и с какой скоростью.
Мне нужен быстрый поиск по ~8Gb текстовых файлов, логика поиска примерно такая же как в нотпад++
NVMeMasterЕсли у тебя тупой алгоритм, Rust тебе не поможет, потому что алгоритм так и останется тупым и, соотвественно, медленным.
Сами коллекции можно как угодно переписать, в том числе в виде библиотеки на Rust
Офлайн
#10 Июль 23, 2021 11:43:10
- NVMeMaster
-
-
- Зарегистрирован: 2021-07-20
- Сообщения: 7
- Репутация:
0
- Профиль Отправить e-mail
Как раскрыть потенциал современных NVMe SSD при сохранении/загрузке коллекций обьектов?
doza_andУточняю:
Вы не приводите никаких требований ни по быстродействию ни по объему памяти, вообще никаких.
Нужно читать с диска blob в том же самом формате в каком он находится в оперативной памяти в Rust, а для Python допустим небольшой оверхед для переупаковки в родные коллекции, строки и прочие обертки над примитивами.
Переносимость win/linux, little/big-endian НЕ НУЖНА. Все будет запускаться на одной и той же машине с 64Gb RAM, память желательно использовать эффективно, но не в ущерб скорости сериализации/десериализации на такой ссд:
Памяти много, а потому БД мне не нужны. Нужны blob-файлы.
Я люблю писать консольные программы в Unix-way стиле.
99% моих наработок написаны на Python и одномоментно все переписать на Rust не представляется возможным (да и не нужно).
В последнее время изучаю Rust потому что он многопоточный и безопасный, а у меня сейчас есть 6 ядер/12 потоков.
Если Python и Rust смогут пользоваться условным общим форматом файлов для данных и кешей то я смогу писать консольные программы на Rust и пользоваться linux piping.
А графические оболочки к ним продолжу писать на Python и pyqt5 или pygtk3
Офлайн
- Начало
- » Python для экспертов
-
» Как раскрыть потенциал современных NVMe SSD при сохранении/загрузке коллекций обьектов?