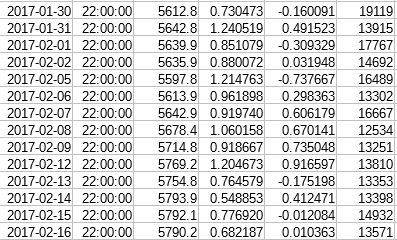
Делаем с ними вот такое:
pandasdf['label'] = pandasdf[forecast_col].shift(-forecast_out) # смещаем данные о цене назад на n строк, "имитируя" будущее X = np.array(pandasdf.drop(['label'], 1)) # features X = preprocessing.scale(X) # нормализуем данные X_lately = X[-forecast_out:] # берём только данные без labels для прогноза X = X[:-forecast_out] # не учитываем данные без labels pandasdf.dropna(inplace=True) # удаляем строки с пустыми значениями y = np.array(pandasdf['label']) # labels X_train, X_test, y_train, y_test = cross_validation.train_test_split(X, y, test_size=0.3) # проходим кросс-валидацию на 30% данных (test_size=0.3) clf = LinearRegression(n_jobs=-1) # указываем классификатор clf.fit(X_train, y_train) # обучаемся accuracy = int(clf.score(X_test, y_test) * 100) # проверяем точность с помощью кросс-валидации forecast_set = clf.predict(X_lately) # предсказываем на последних/неизвестных данных
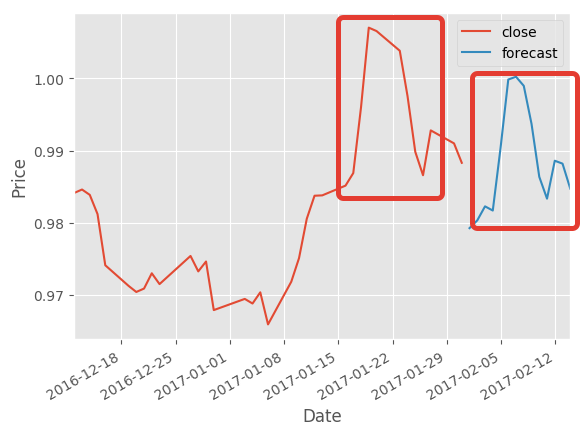
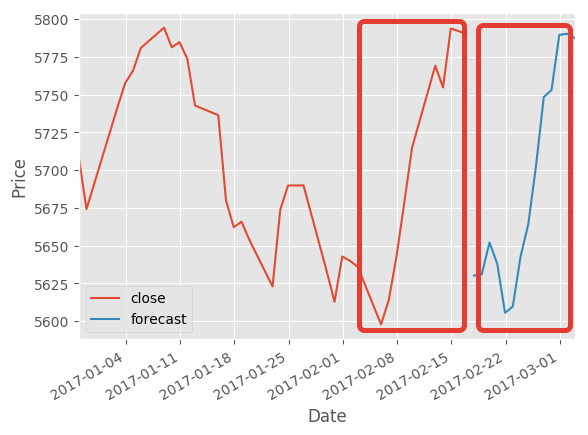
И получаем “предсказание” прошлого с точностью 95%: