В данный момент оно реализовано на простом pickle
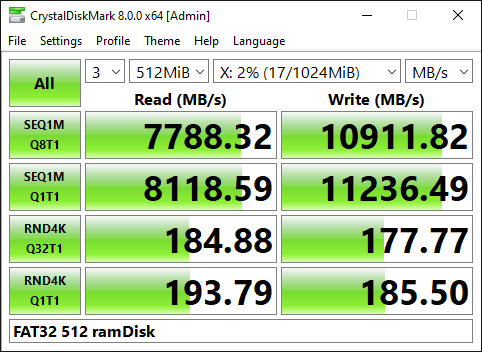
Мне нужен быстрый поиск по ~8Gb текстовых файлов, логика поиска примерно такая же как в нотпад++
Только у меня индексы строятся заранее, а не в момент поиска.
Содержимое файлов загружается лениво (предпросмотр сделан на pyqt5 точно как на скриншоте. но графический режим и предпросмотр используется не всегда)
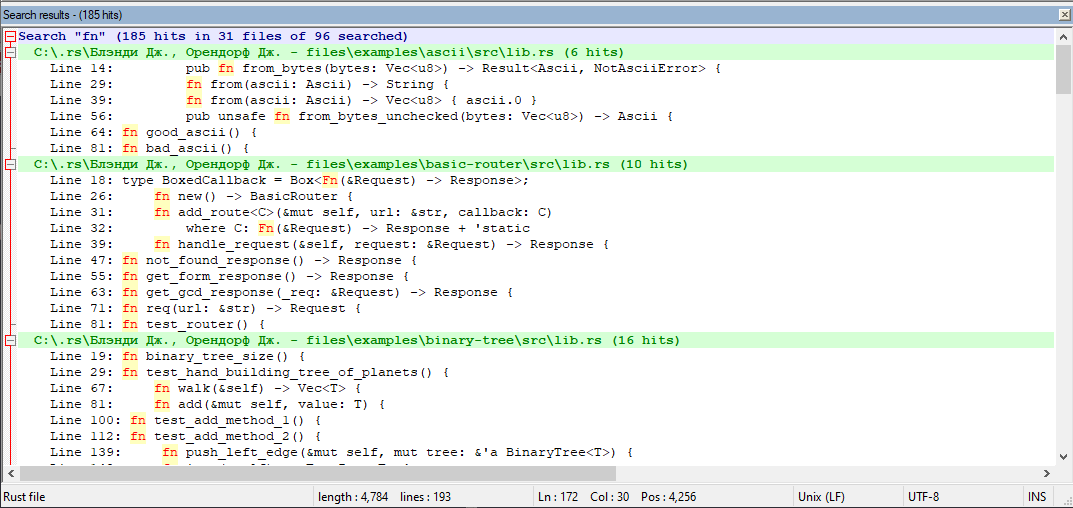
Если попытаться перевести скриншот в сишную структуру получится следующее:
struct SearchResult {
int file_path_hash; //file_path_hash == Python hash(file_path)
int str_start_index;
int line_number; //добавлено для предпросмотра в стиле нотпад++
int line_str_start_index; //для предпросмотра в стиле нотпад++
}
find_string будет именем файла, ну а содержимое файла - массив структур
Как видно я совсем отказался от хранения строки с file_path.
Вместо имени файла храню хеш пути к файлу и использую словарь int file_path_hash -> file_path в отдельном файле. (эту логику не нужно переписывать с Python на си)
Сейчас нужно компактно упаковать struct SearchResult в памяти.
А поскольку я выбросил все строки можно попробовать хранить это все в ПЛОСКОМ numpy.array
Вот так оно сериализуется в файл:
arr = np.array([
2147483647, ord('a'), ord('b'), ord('c'),
2147483647 - 1, ord('q'), ord('w'), ord('e'),
2147483647 - 2, ord('a'), ord('s'), ord('d'),
2147483647 - 3, ord('z'), ord('x'), 2147483647
])
file_name = 'np_array.dat'
np.save(open(file_name, 'wb'), arr)